Simulating the Spread of Disease
In this post, I’m going to discuss another simulation in Python to demonstrate an infectious disease spreading in a population. The source code for the simulation can be found in the Github repository here. I also want to acknowledge Professor Justin Bois at Caltech for writing the software package iqplot and for his guidance in data analysis over the past few years.
Why the Geometric Distribution?
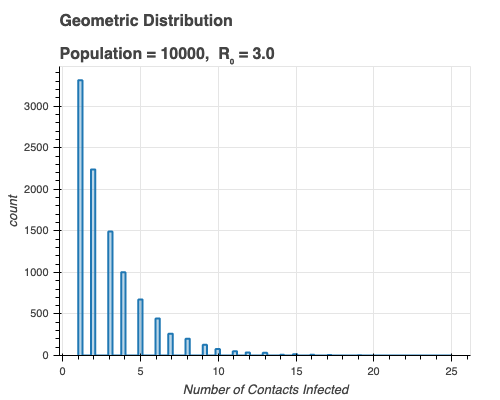
I used the geometric distribution to model the number of infected contacts of each person. $R_0$ is the average number of people infected by each infected person, but there will naturally be variation. If $R_0 = 3$, not everyone infects exactly $3$ people. Many biological systems are modeled by a normal distribution, which is symmetric about the mean. However, in a distribution of infected contacts, most people are likely to infect around $3$ susceptible individuals, and far fewer people will infect large numbers of people. Therefore, we need a distribution that is asymmetric about the mean.
We also need a discrete distribution, rather than a continuous one. A discrete distribution only allows integer numbers, which makes sense because people can't infect i.e. $3.5$ people. However, the average $R_0$ can be a decimal, like $R_0$ for SARS-CoV-2, which is probably between $2$ and $3$. We also need a distribution that describes things that can be counted. That is, the intended distribution shouldn't support negative numbers because we can't count a negative number of people.
The geometric distribution is discrete, supports non-negative or only positive integers, and has a heavy positive tail. A good description with a biological example is given in this distribution explorer created by Justin Bois. Let's suppose that a given infected person has a constant probability of infecting another person they come into contact with. Over the course of the person's infection, they will infect some number of people. This number is described by the geometric distribution.
The probability mass function (PMF) of a discrete distribution gives the probability of getting a certain value out of the distribution. The sum of the probabilities of getting each number should add up to $1$ because total probability sums to $1$. The PMF of the geometric distribution is
The parameter $p$ is the probability of getting a "success." The PMF gives the probability of getting $k-1$ failures before your first success. Let's suppose that you're flipping a fair coin, and you want to get heads. Then heads is considered a success, and tails is a failure. For a fair coin, $p = 0.5$. Then you can compute the probability that you get heads on the first, second, third, etc. tries. Mathematically, this is represented as getting $k-1$ tails followed by a single flip of heads. The range of possibilities is getting heads on the first flip ($k = 1$) and waiting a very large number of flips before the first head ($k >> 1$). The mean of the distribution is $\frac{1}{p}$. For the coin situation, that means you would expect to get heads on your second try.
We assume that when an infected and an uninfected person are in contact, the probability of transmitting the infection is the same. Due to randomness, different people infect different numbers of their contacts. This randomness accounts for different behaviors among people. Some people will be super-spreaders and infect large numbers of people at large gatherings or because they interact with many people on a regular basis. Others are micro-spreaders, who only infect a few people, like those in their household. In the geometric distribution that I used in the simulation, the outputs are all positive integers. Therefore, an infected person in this simulation spreads it to at least one other person.
Simulation Set Up
In this simulation, we start with a constant population into which an infection has not yet been introduced. Throughout the simulation, no one enters or leaves the population (except at the beginning to bring the infection in), and no births or deaths occur. I have also assumed that when people recover from the infection, they have sterilizing immunity, which means they are fully protected and can't be infected again. This prevents them from transmitting it to susceptible individuals.
This interactive web app allows users to explore the effects of various parameters on the outbreak dynamics. It takes a few seconds to open a connection and load the dashboard, so it will not appear immediately. You can change the population size, number of infected people at the start of the outbreak, proportion of people who have immunity beforehand, death rate, duration of the infection, and when people are spreading the pathogen. When you have adjusted the parameters to your liking, click the green Update Dashboard button. The output is a plot of the geometric distribution for a given $R_0$ (to see how many people each person infects if they get sick) and a plot of the cumulative infected, immune, recovered, and dead people during the outbreak.
In general, people are infectious 1-2 days after they have been exposed because they have to replicate enough virus or bacteria in order to easily spread it to others around them. Every person in the population is associated with a number of people they will infect (randomly drawn from the geometric distribution). During the infectious period of each person, this number of contacts will be infected. The epidemic continues until no infected people remain.
Playing with the Parameters
Since the simulation is performed through random sampling, the same set of parameters will not always give the same results. It is also possible that the initial infected people only encounter immune or already infected individuals, so the outbreak fizzles out quickly. You can do things like making $R_0$ larger, increasing the number of initially infected people, and reducing the level of pre-existing immunity to kickstart the outbreak.
Approximation of the SIRDC Model
In the end, we see that this random simulation loosely approximates the SIRDC model, which stands for Susceptible, Infectious, Resolving, Dead, and ReCovered. These are the five subpopulations that people can be in throughout the outbreak. The resolving and infectious groups are both infected with the pathogen, but the resolving group is no longer spreading it to others. At the end of the resolving period, they either die or recover from the illness.
The model is a system of differential equations describing how the sizes of the five subpopulations change over time. Differential equations are set up using the rate of change of a population at a given moment in time.
Derivation
To derive the SIRDC model, we note all the variables affecting each of the five populations:
- Susceptible: people only leave the susceptible population when they get sick.
- Infectious: people enter the infectious group only from the susceptible group, and they move to the resolving group.
- Resolving: people must come from the infectious group only, and then they move to the recovered or dead groups.
- Dead: people must come from the resolving group only, and that is the end.
- Recovered: people must come from the resolving group only, and that is the end.
The greek letters $\beta$, $\gamma$, $\theta$, and $\delta$ in the diagram below are the rates at which people move between the groups, which I will explain later. For simplicity, I have also assumed that the infection lasts for 14 days (the time that you test positive), but each person is only infectious (spreading the disease to others) for 6 days. The resolved group isn't a distinct group. The dead and recovered groups together make the resolved group.
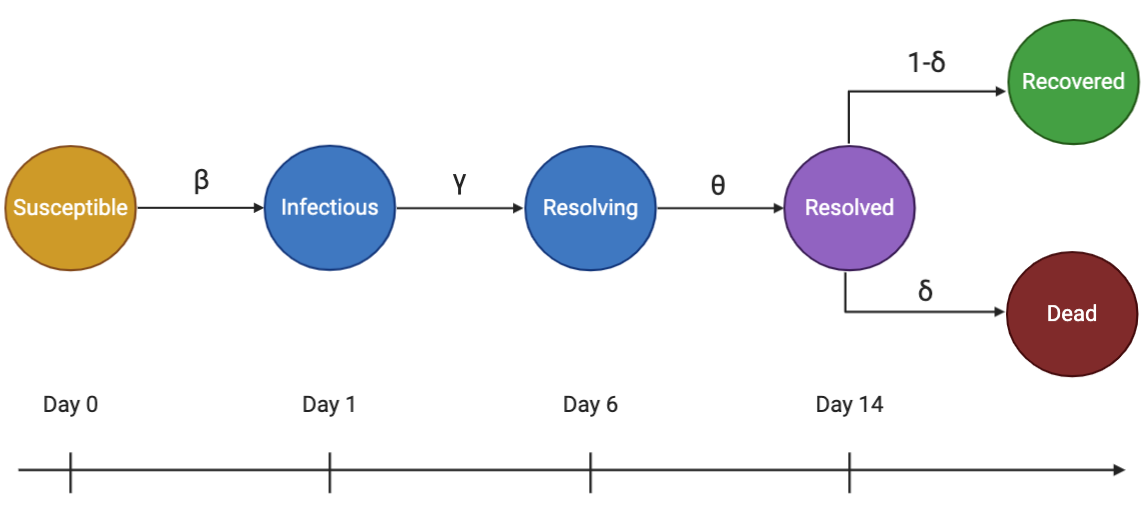
People are infected with probability $\beta$, become non-infectious (resolving) at a rate of $\gamma$, finish the illness at a rate of $\theta$, and die at a rate of $\delta$ from the illness. The rates are the inverses of the durations of each period in the infection cycle.
The rates of change of the populations are the derivatives, $\frac{\mathrm{d}S}{\mathrm{d}t}$, $\frac{\mathrm{d}I}{\mathrm{d}t}$, $\frac{\mathrm{d}R}{\mathrm{d}t}$, $\frac{\mathrm{d}D}{\mathrm{d}t}$, and $\frac{\mathrm{d}C}{\mathrm{d}t}$. The four Greek letters are the rate parameters, and $S$, $I$, $R$, $D$, and $C$ are the subpopulation sizes. The constant $N$ is the size of the whole population. The constant rate parameters are as follows:
- $\beta \;$: rate of infection in units of people per day. It is equal to $R_0$, the average number of people that each person infects, divided by the duration of the infectious period.
- $\gamma \;$: rate at which people become non-infectious, which is the inverse of the duration of the infectious period.
- $\theta \;$: rate at which these resolving infections become resolved, which is the inverse of the duration of the non-infectious period.
- $\delta \;$: death rate
In the model, $\beta$ is defined using $R_0$, which is an average value. However, in real life, each person will infect a variable number of people, depending on their behavior and number of close contacts. The parameters for a scenario in which $R_0 = 3$, the infection lasts 14 days, people are infectious for the first 6 days, and the probability of dying is 10%, are
\[\begin{align*} \beta = \frac{3}{6} \end{align*}\] \[\begin{align*} \gamma = \frac{1}{6} \end{align*}\] \[\begin{align*} \theta = \frac{1}{8} \end{align*}\] \[\begin{align*} \delta = 0.1 \end{align*}\]The rate of change of the susceptible population is dependent on 3 things -- the current size of the susceptible population, $\beta$, and the proportion of infected individuals in the population. If you were to measure how likely you are to catch SARS-CoV-2, you have to know what proportion of your local population is currently infected and the probability that you get infected if you get exposed. We multiply these three variables to get the rate of change. Then if any of the variables is 0, the susceptible population will not change, which makes sense.
The infectious population increases by the same amount that the susceptible population decreases, and it decreases by the same amount that the resolving group increases. The resolving group decreases when people finish their illness. Resolving, recovery, and death for each person are independent of everyone else, so we don't need to consider proportions of the population, only the product of the rate and the population. The infectious group decreases by $\gamma I$, and the resolving group decreases by $\theta R$.
The recovered group changes only when people from the infected group recover at a rate of $\gamma I$, and the dead group changes only when people from the infected group die at a rate of $\mu I$.
If we add up the four derivatives, we get 0. This makes sense because the overall population is constant. At all times, $S + I + R + D + C = N$, so $\frac{\mathrm{d}S}{\mathrm{d}t} + \frac{\mathrm{d}I}{\mathrm{d}t} + \frac{\mathrm{d}R}{\mathrm{d}t} + \frac{\mathrm{d}D}{\mathrm{d}t} + \frac{\mathrm{d}C}{\mathrm{d}t} = \frac{\mathrm{d}N}{\mathrm{d}t} = 0$.
Evaluation with Parameters
Now that we have our system of differential equations, we need five corresponding initial conditions in order to solve them. The differential equations give the rate of change of the populations, but we need to know where the populations start. To get the initial conditions, we make some reasonable assumptions about the initial state of the population.
Let's suppose the whole population is $10,000$ people. Five people bring a virus to the home population from elsewhere, becoming the first cases. So the infected population at the outset is $5$, or $I(0) = 5$. No one has died or recovered from the infection yet, so $R(0) = D(0) = C(0) = 0$. Finally, the susceptible people are everyone who is not infected, recovered, or dead, so $S(0) = 9,995$.
We will use the parameters discussed above, $\beta = \frac{3}{6}$, $\gamma = \frac{1}{6}$, $\theta = \frac{1}{8}$, and $\delta = 0.1$. So each infected person infects an average of $3$ people in $6$ days (the infectious period), and a sick person has a $10$% chance of dying of the disease. Death and recovery happen $14$ days after infection once the illness has run its course, so we divide the proportions by the duration of the illness. Finally, putting all the equations, parameters, and initial conditions together, we get
Using numerical methods, we can solve the initial value problem above and get the sizes of the subpopulations throughout the outbreak. We then plot the results for the four groups, and we can compare it to the simulation results. The infectious and resolving groups are combined into the total "Infected" group because both groups are actively infected.
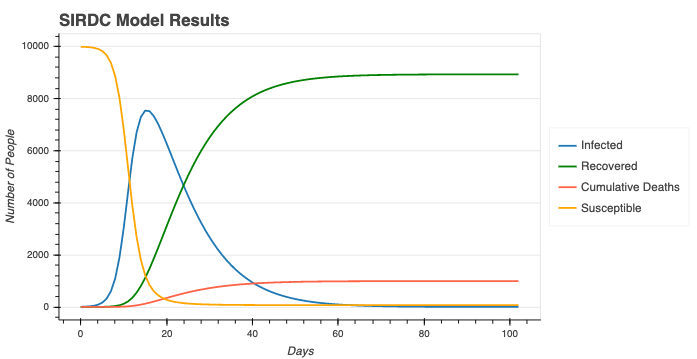
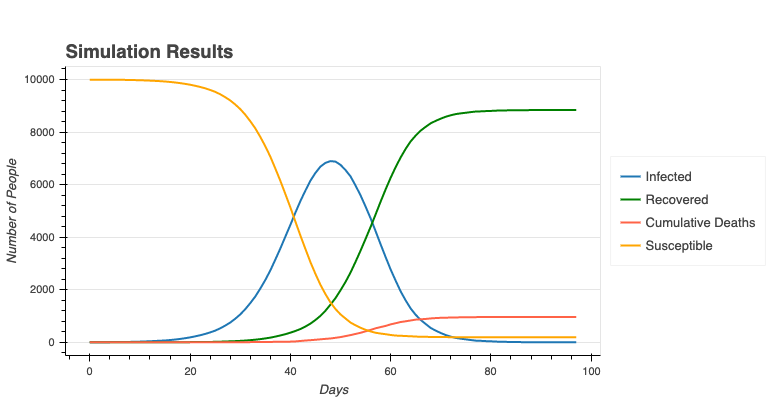
The curves are overall a similar shape in the two plots with similar time scales. The variation can be attributed to randomness in the simulation. The number of infections in the simulation rises slower because of the variation in $R_0$. In the model, $R_0$ is always $3$, but in the simulation (and in real life), the number of infected contacts of each person is not $3$, as we see in the associated geometric distribution plot below:
Deaths do not occur at precisely $10$% in the simulation. I essentially flipped a biased coin to determine whether or not an individual would die, with a $10$% chance of it landing on death. In a large population, the overall number of deaths will be approximately, but not exactly, $10$%.
Epidemiological models are useful for predicting how an outbreak may unfold, but simple models like the SIRDC model do not take into account variation among individuals and changing behavior over time. The more sophisticated models used to predict the trajectory of the COVID-19 pandemic often use artificial intelligence to predict how people may behave on an individual level and alter the outcome of the pandemic. The simulation in this post incorporates some randomization, but it is limited because it assumes that the population is well-mixed and that people behave in the same way throughout the entire outbreak. However, it is still a useful tool to understand the basics of disease spread and explore the effects of different parameters.
Leave a Comment